
Search Engine Submission Tips
This section of Search Engine Watch (formerly called A Webmaster's Guide To Search Engines) is primarily for webmasters, site owners and web marketers. It covers search engine submission, placement and marketing issues. It explains how search engines find and rank web pages, with an emphasis on what webmasters can do to improve their search engine rankings by properly submitting, using better page design, HTML meta tags, and other tips.
Search Engine Watch members have access to in-depth information about submission issues and get extra benefits. |
If this is your first visit, it's recommended that you read the pages in this section in the order shown. That will best introduce you to the important concepts of search engine submission and optimization. Navigational links at the bottom of each page will allow you to easily load the next one.
By Danny Sullivan, Editor
October 14, 2002
Updated: October 14, 2002
Search engines are one of the primary ways that Internet users find web sites. That's why a web site with good search engine listings may see a dramatic increase in traffic.
Everyone wants those good listings. Unfortunately, many web sites appear poorly in search engine rankings or may not be listed at all because they fail to consider how search engines work.
In particular, submitting to search engines (as covered in the Essentials section) is only part of the challenge of getting good search engine positioning. It's also important to prepare a web site through "search engine optimization."
Search engine optimization means ensuring that your web pages are accessible to search engines and focused in ways that help improve the chances they will be found.
Search Engine Watch members have access to in-depth information about submission issues and get extra benefits. |
This next section provides information, techniques and a good grounding in the basics of search engine optimization. By using this information where appropriate, you may tap into visitors who previously missed your site.
The guide is not a primer on ways to trick or "spam" the search engines. In fact, there aren't "search engine secrets" that will guarantee a top listing. But there are a number of small changes you can make that can sometimes produce big results.
Let's go forward and explore first the two major ways search engines get their listings, then see how search engine optimization can especially help with crawler-based search engines.
Content you'll read in this "Submission Tips" section is also available via a PDF report, making it easy to download everything at once and print for offline reading. |
How Search Engines Work
By Danny Sullivan, Editor
October 14, 2002
The term "search engine" is often used generically to describe both crawler-based search engines and human-powered directories. These two types of search engines gather their listings in radically different ways.
Crawler-Based Search Engines
Crawler-based search engines, such as Google, create their listings automatically. They "crawl" or "spider" the web, then people search through what they have found.
If you change your web pages, crawler-based search engines eventually find these changes, and that can affect how you are listed. Page titles, body copy and other elements all play a role.
Human-Powered Directories
A human-powered directory, such as the Open Directory, depends on humans for its listings. You submit a short description to the directory for your entire site, or editors write one for sites they review. A search looks for matches only in the descriptions submitted.
Changing your web pages has no effect on your listing. Things that are useful for improving a listing with a search engine have nothing to do with improving a listing in a directory. The only exception is that a good site, with good content, might be more likely to get reviewed for free than a poor site.
"Hybrid Search Engines" Or Mixed Results
In the web's early days, it used to be that a search engine either presented crawler-based results or human-powered listings. Today, it extremely common for both types of results to be presented. Usually, a hybrid search engine will favor one type of listings over another. For example, MSN Search is more likely to present human-powered listings from LookSmart. However, it does also present crawler-based results (as provided by Inktomi), especially for more obscure queries.
Search Engine Watch members have access to the How Search Engines Work section, which describes how each major search engine makes use of crawling the web, humans editors and how to submit properly. |
The Parts Of A Crawler-Based Search Engine
Crawler-based search engines have three major elements. First is the spider, also called the crawler. The spider visits a web page, reads it, and then follows links to other pages within the site. This is what it means when someone refers to a site being "spidered" or "crawled." The spider returns to the site on a regular basis, such as every month or two, to look for changes.
Everything the spider finds goes into the second part of the search engine, the index. The index, sometimes called the catalog, is like a giant book containing a copy of every web page that the spider finds. If a web page changes, then this book is updated with new information.
Sometimes it can take a while for new pages or changes that the spider finds to be added to the index. Thus, a web page may have been "spidered" but not yet "indexed." Until it is indexed -- added to the index -- it is not available to those searching with the search engine.
Search engine software is the third part of a search engine. This is the program that sifts through the millions of pages recorded in the index to find matches to a search and rank them in order of what it believes is most relevant. You can learn more about how search engine software ranks web pages on the aptly-named How Search Engines Rank Web Pages page.
Major Search Engines: The Same, But Different
All crawler-based search engines have the basic parts described above, but there are differences in how these parts are tuned. That is why the same search on different search engines often produces different results. Some of the significant differences between the major crawler-based search engines are summarized on the Search Engine Features Page. Information on this page has been drawn from the help pages of each search engine, along with knowledge gained from articles, reviews, books, independent research, tips from others and additional information received directly from the various search engines.
Now let's look more about how crawler-based search engine rank the listings that they gather.
Next: How Search Engines Rank Web Pages
How Search Engines Work
By Danny Sullivan, Editor
October 14, 2002
The term "search engine" is often used generically to describe both crawler-based search engines and human-powered directories. These two types of search engines gather their listings in radically different ways.
Crawler-Based Search Engines
Crawler-based search engines, such as Google, create their listings automatically. They "crawl" or "spider" the web, then people search through what they have found.
If you change your web pages, crawler-based search engines eventually find these changes, and that can affect how you are listed. Page titles, body copy and other elements all play a role.
Human-Powered Directories
A human-powered directory, such as the Open Directory, depends on humans for its listings. You submit a short description to the directory for your entire site, or editors write one for sites they review. A search looks for matches only in the descriptions submitted.
Changing your web pages has no effect on your listing. Things that are useful for improving a listing with a search engine have nothing to do with improving a listing in a directory. The only exception is that a good site, with good content, might be more likely to get reviewed for free than a poor site.
"Hybrid Search Engines" Or Mixed Results
In the web's early days, it used to be that a search engine either presented crawler-based results or human-powered listings. Today, it extremely common for both types of results to be presented. Usually, a hybrid search engine will favor one type of listings over another. For example, MSN Search is more likely to present human-powered listings from LookSmart. However, it does also present crawler-based results (as provided by Inktomi), especially for more obscure queries.
Search Engine Watch members have access to the How Search Engines Work section, which describes how each major search engine makes use of crawling the web, humans editors and how to submit properly. |
The Parts Of A Crawler-Based Search Engine
Crawler-based search engines have three major elements. First is the spider, also called the crawler. The spider visits a web page, reads it, and then follows links to other pages within the site. This is what it means when someone refers to a site being "spidered" or "crawled." The spider returns to the site on a regular basis, such as every month or two, to look for changes.
Everything the spider finds goes into the second part of the search engine, the index. The index, sometimes called the catalog, is like a giant book containing a copy of every web page that the spider finds. If a web page changes, then this book is updated with new information.
Sometimes it can take a while for new pages or changes that the spider finds to be added to the index. Thus, a web page may have been "spidered" but not yet "indexed." Until it is indexed -- added to the index -- it is not available to those searching with the search engine.
Search engine software is the third part of a search engine. This is the program that sifts through the millions of pages recorded in the index to find matches to a search and rank them in order of what it believes is most relevant. You can learn more about how search engine software ranks web pages on the aptly-named How Search Engines Rank Web Pages page.
Major Search Engines: The Same, But Different
All crawler-based search engines have the basic parts described above, but there are differences in how these parts are tuned. That is why the same search on different search engines often produces different results. Some of the significant differences between the major crawler-based search engines are summarized on the Search Engine Features Page. Information on this page has been drawn from the help pages of each search engine, along with knowledge gained from articles, reviews, books, independent research, tips from others and additional information received directly from the various search engines.
Now let's look more about how crawler-based search engine rank the listings that they gather.
Next: How Search Engines Rank Web Pages
Search Engine Placement Tips
By Danny Sullivan, Editor
October 14, 2002
Updated: October 14, 2002
A query on a crawler-based search engine often turns up thousands or even millions of matching web pages. In many cases, only the 10 most "relevant" matches are displayed on the first page.
Naturally, anyone who runs a web site wants to be in the "top ten" results. This is because most users will find a result they like in the top ten. Being listed 11 or beyond means that many people may miss your web site.
The tips below will help you come closer to this goal, both for the keywords you think are important and for phrases you may not even be anticipating.
Pick Your Target Keywords
How do you think people will search for your web page? The words you imagine them typing into the search box are your target keywords.
For example, say you have a page devoted to stamp collecting. Anytime someone types "stamp collecting," you want your page to be in the top ten results. Then those are your target keywords for that page.
Each page in your web site will have different target keywords that reflect the page's content. For example, say you have another page about the history of stamps. Then "stamp history" might be your keywords for that page.
Your target keywords should always be at least two or more words long. Usually, too many sites will be relevant for a single word, such as "stamps." This "competition" means your odds of success are lower. Don't waste your time fighting the odds. Pick phrases of two or more words, and you'll have a better shot at success.
The Researching Keywords article available to Search Engine Watch members provides additional information about selecting key terms. |
Make sure your target keywords appear in the crucial locations on your web pages. The page's HTML title tag is most important. Failure to put target keywords in the title tag is the main reason why perfectly relevant web pages may be poorly ranked. More about the title tag can be found on the How HTML Meta Tags Work page.
Build your titles around the top two or three phrases that you would like the page to be found for. The titles should be relatively short and attractive. Think of newspaper headlines. With a few words, they make you want to read a story. Similarly, your page titles are like headlines for your pages. They appear in search engine listings, and a short, attractive title may help make users click through to your site.
Search engines also like pages where keywords appear "high" on the page, as described more fully on the Search Engine Ranking page. To accommodate them, use your target keywords for your page headline, if possible. Have them also appear in the first paragraphs of your web page.
Keep in mind that tables can "push" your text further down the page, making keywords less relevant because they appear lower on the page. This is because tables break apart when search engines read them. For example, picture a typical two-column page, where the first column has navigational links, while the second column has the keyword loaded text. Humans see that page like this:
Home
Stamp Collecting
Page 1
Page
2 Stamp collection is worldwide experience.
Page 3
Thousands enjoy it everyday, and millions
Page 4
can be made from this hobby/business.
Search engines (and those with old browsers) see the page like this:
Home
Page 1
Page 2
Page 3
Page 4
Stamp
Collecting
Stamp collection is worldwide experience.
Thousands enjoy it everyday, and millions
can be made from this
hobby/business.
See how the keywords have moved down the page? There's no easy way around this, other than to simplifying your table structure. Consider how tables might affect your page, but don't necessarily stop using them. I like tables, and I'll continue to use them.
Large sections of JavaScript can also have the same effect as tables. The search engine reads this information first, which causes the normal HTML text to appear lower on the page. Place your script further down on the page, if possible.
The Hiding JavaScript article available to Search Engine Watch members provides additional information about JavaScript and search engines. |
Have Relevant Content
Changing your page titles is not necessarily going to help your page do well for your target keywords if the page has nothing to do with the topic. Your keywords need to be reflected in the page's content.
In particular, that means you need HTML text on your page. Sometimes sites present large sections of copy via graphics. It looks pretty, but search engines can't read those graphics. That means they miss out on text that might make your site more relevant. Some of the search engines will index ALT text and comment information. But to be safe, use HTML text whenever possible. Some of your human visitors will appreciate it, also.
Be sure that your HTML text is "visible." Some designers try to spam search engines by repeating keywords in a tiny font or in the same color at the background color to make the text invisible to browsers. Search engines are catching on to these and other tricks. Expect that if the text is not visible in a browser, then it may not be indexed by a search engine.
Finally, consider "expanding" your text references, where appropriate. For example, a stamp collecting page might have references to "collectors" and "collecting." Expanding these references to "stamp collectors" and "stamp collecting" reinforces your strategic keywords in a legitimate and natural manner. Your page really is about stamp collecting, but edits may have reduced its relevancy unintentionally.
An excellent resource for more about writing copy that naturally pleases search engines is the free High Rankings Advisornewsletter. Consider signing up for it.
Avoid Search Engine Stumbling Blocks
Some search engines see the web the way someone using a very old browser might. They may not read image maps. They may not read frames. You need to anticipate these problems, or a search engine may not index any or all your web pages.
Have HTML links
Often, designers create only image map links from the home page to inside pages. A search engine that can't follow these links won't be able to get "inside" the site. Unfortunately, the most descriptive, relevant pages are often inside pages rather than the home page.
Solve this problem by adding some HTML hyperlinks to the home page that lead to major inside pages or sections of your web site. This is something that will help some of your human visitors, also. Put them down at the bottom of the page. The search engine will find them and follow them.
Also consider making a site map page with text links to everything in your web site. You can submit this page, which will help the search engines locate pages within your web site.
Finally, be sure you do a good job of linking internally between your pages. If you naturally point to different pages from within your site, you increase the odds that search engines will follow links and find more of your web site.
Frames can kill
Some of the major search engines cannot follow frame links. Make sure there is an alternative method for them to enter and index your site, either through meta tags or smart design. For more information, see the tips on using frames.
Dynamic Doorblocks
Generating pages via CGI or database-delivery? Expect that some of the search engines won't be able to index them. Consider creating static pages whenever possible, perhaps using the database to update the pages, not to generate them on the fly. Also, avoid symbols in your URLs, especially the ? symbol. Search engines tend to choke on it.
The Search Engines And Dynamic Pages article available to Search Engine Watch members provides additional information about testing for and solving dynamic delivery problems. |
Every major search engine uses link analysis as part of their ranking algorithms. This is done because its very difficult for webmasters to "fake" good links, in the way they might try to spam search engines by manipulating the words on their web pages. As a result, link analysis gives search engines a useful means of determining which pages are good for particular topics.
By building links, you can help improve how well your pages do in link analysis systems. The key is understanding that link analysis is not about "popularity." In other words, it's not an issue of getting lots of links from anywhere. Instead, you want links from good web pages that are related to the topics you want to be found for.
Here's the simple means to find those good links. Go to the major search engines. Search for your target keywords. Look at the pages that appear in the top results. Now visit those pages and ask the site owners if they will link to you. Not everyone will, especially sites that are extremely competitive with you. However, there will be non-competitive sites that will link to you -- especially if you offer to link back.
Why is this system good? By searching for your target keywords, you'll find the pages that the search engines themselves are telling you are good, as evidenced by the fact that they rank well. Hence, links from these pages are more important -- and important for the terms you are interested in -- than links from other pages. In addition, if these pages are top ranked, then they are likely to be receiving many visitors. Thus, if you can gain links from them, you might receive some visitors who initially go to those pages.
The More About Link Analysispage available to Search Engine Watch members provides in-depth advice on building relevant links to your web site. |
Just Say No To Search Engine Spamming
For one thing, spamming doesn't always work with search engines. It can also backfire. Search engines may detect your spamming attempt and penalize or ban your page from their listings.
Also, search engine spamming attempts usually center around being top ranked for extremely popular keywords. You can try and fight that battle against other sites, but then be prepared to spend a lot of time each week, if not each day, defending your ranking. That effort usually would be better spent on networking and alternative forms of publicity, described below.
If those practical reasons aren't enough, how about some ethical ones? The content of most web pages ought to be enough for search engines to determine relevancy without webmasters having to resort to repeating keywords for no reason other than to try and "beat" other web pages. The stakes will simply keep rising, and users will also begin to hate sites that undertake these measures.
Consider search engine spamming against spam mail. No one likes spam mail, and sites that use spam mail services often face a backlash from those on the receiving end. Sites that spam search engines degrade the value of search engine listings. As the problem grows, these sites may face the same backlash that spam mail generates.
Submit Your Key Pages
Most search engines will index the other pages from your web site by following links from a page you submit to them. But sometimes they miss, so it's good to submit the top two or three pages that best summarize your web site.
Don't trust the submission process to automated programs and services. Some of them are excellent, but the major search engines are too important. There aren't that many, so submit manually, so that you can see if there are any problems reported.
Also, don't bother submitting more than the top two or three pages. It doesn't speed up the process. Submitting alternative pages is only insurance. In case the search engine has trouble reaching one of the pages, you've covered yourself by giving it another page from which to begin its crawl of your site.
Be patient. It can take up to a month to two months for your "non-submitted" pages to appear in a search engine, and some search engines may not list every page from your site.
Detailed information about submitting to each major search engine is available to Search Engine Watch members. |
Verify And Maintain Your Listing
Check on your pages and ensure they get listed, in the ways described on the Check URL page. Once your pages are listed in a search engine, monitor your listing every week or two. Strange things happen. Pages disappear from catalogs. Links go screwy. Watch for trouble, and resubmit if you spot it.
Resubmit your site any time you make significant changes. Search engines should revisit on a regular schedule. However, some search engines have grown smart enough to realize some sites only change content once or twice a year, so they may visit less often. Resubmitting after major changes will help ensure that your site's content is kept current.
Beyond Search Engines
It's worth taking the time to make your site more search engine friendly, because some simple changes may pay off with big results. Even if you don't come up in the top ten for your target keywords, you may find an improvement for target keywords you aren't anticipating. The addition of just one extra word can suddenly make a site appear more relevant, and it can be impossible to guess what that word will be.
Also, remember that while search engines are a primary way people look for web sites, but they are not the only way. People also find sites through word-of-mouth, traditional advertising, the traditional media, newsgroup postings, web directories and links from other sites. Many times, these alternative forms are far more effective draws than are search engines.
Finally, know when it's time to call it quits. A few changes may be enough to make you tops in one or two search engines. But that's not enough for some people, and they will invest days creating special pages and changing their sites to try and do better. This time could usually be put to better use pursuing non-search engine publicity methods.
Don't obsess over your ranking. Even if you follow every tip and find no improvement, you still have gained something. You will know that search engines are not the way you'll be attracting traffic. You can concentrate your efforts in more productive areas, rather than wasting your valuable time.
Next: How To Use HTML Meta Tags
How To Use HTML Meta Tags
By Danny Sullivan, Editor
December 5, 2002
Want to get a top ranking in search engines? No problem! All you need to do is add a few magical "meta tags" to your web pages, and you'll skyrocket to the top of the listings.
If only it were so easy. Let's make it clear:
Meta tags have never been a guaranteed way to gain a top ranking on crawler-based search engines. Today, the most valuable feature they offer the web site owner is the ability to control to some degree how their web pages are described by some search engines. They also offer the ability to prevent pages from being indexed at all. This page explores these and other meta tag-related features in more depth.
What are meta tags? They are information inserted into the "head" area of your web pages. Other than the title tag (explained below), information in the head area of your web pages is not seen by those viewing your pages in browsers. Instead, meta information in this area is used to communicate information that a human visitor may not be concerned with. Meta tags, for example, can tell a browser what "character set" to use or whether a web page has self-rated itself in terms of adult content.
Let's see two common types of meta tags, then we'll discuss exactly how they are used in more depth:
In the example above, you can see the beginning of the page's "head" area as noted by the HEAD tag -- it ends at the portion shown as /HEAD.
Meta tags go in between the "opening" and "closing" HEAD tags. Shown in the example is a TITLE tag, then a META DESCRIPTION tag, then a META KEYWORDS tag. Let's talk about what these do.
The HTML title tag isn't really a meta tag, but it's worth discussing in relation to them. Whatever text you place in the title tag (between the TITLE and /TITLE portions as shown in the example) will appear in the reverse bar of someone's browser when they view the web page. For instance, within the title tag of this page that you are reading is this text:
How To Use HTML Meta Tags
If you look at the reverse bar in your browser, then you should see that text being used, similar to this:
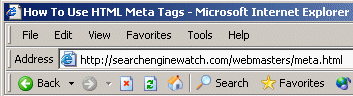
Some browsers also supplement whatever you put in the title tag by adding their own name, as you can see Microsoft's Internet Explorer doing in the picture above.
The title tag is also used as the words to describe your page when someone adds it to their "Favorites" or "Bookmarks" lists. For instance, if you added this page to your Favorites in Internet Explorer, it would show up like this:
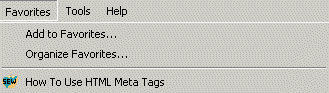
How did that little Search Engine Watch logo also show up? Everyone always asks. The article below provides more help:
Creating Your Own Favicon.ico Icon For IE5
Web Developer's Journal, March 7, 2000
http://www.webdevelopersjournal.com/articles/favicon.html
But what about search engines! The title tag is crucial for them. The text you use in the title tag is one of the most important factors in how a search engine may decide to rank your web page (see the Search Engine Placement Tips section for more details). In addition, all major crawlers will use the text of your title tag as the text they use for the title of your page in your listings.
For example, this is how Teoma lists the page you are reading:
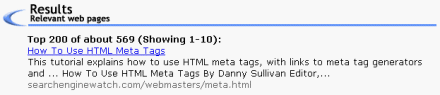
You can see that the text "How To Use HTML Meta Tags" is used as the hyperlinked title of this page's listed in Teoma's results.
In review, think about the key terms you'd like your page to be found for in crawler-based search engines, then incorporate those terms into your title tag in a short, descriptive fashion. That text will then be used as your title in crawler-based search engines, as well as the title in bookmarks and in browser reverse bars.
The meta description tag allows you to influence the description of your page in the crawlers that support the tag (these are listed on the Search Engine Features page).
Look back at the example of a meta tag. See the first meta tag shown, the one that says "name=description"? That's the meta description tag. The text you want to be shown as your description goes between the quotation marks after the "content=" portion of the tag (generally, 200 to 250 characters may be indexed, though only a smaller portion of this amount may be displayed).
For this page you are reading, I would like it described in a search engine's listings like this:
This tutorial explains how to use HTML meta tags, with links
to meta tag generators and builders. From SearchEngineWatch.com,
a guide to search engine submission and registration.
Will this happen? Not with every search engine. For example, Google ignores the meta description tag and instead will automatically generate its own description for this page. Others may support it partially. For instance, let's see again how this page is listed in Teoma:
You can see that the first portion of the page's description comes from the meta description tag, then there's an ellipse (.), and the remaining portion is drawn from the body copy of the page itself.
In review, it is worthwhile to use the meta description tag for your pages, because it gives you some degree of control with various crawlers. An easy way to do this often is to take the first sentence or two of body copy from your web page and use that for the meta description content.
The meta keywords tag allows you to provide additional text for crawler-based search engines to index along with your body copy. How does this help you? Well, for most major crawlers, it doesn't. That's because most crawlers now ignore the tag. The few supporting it can be found on the Search Engine Features page).
The meta keywords tag is sometimes useful as a way to reinforce the terms you think a page is important for ON THE FEW CRAWLERS THAT SUPPORT IT. For instance, if you had a page about stamp collecting -- AND you say the words stamp collecting at various places in your body copy -- then mentioning the words "stamp collecting" in the meta keywords tag MIGHT help boost your page a bit higher for those words.
Remember, if you don't use the words "stamp collecting" on the page at all, then just adding them to the meta keywords tag is extremely unlikely to help the page do well for the term. The text in the meta keywords tag, FOR THE FEW CRAWLERS THAT SUPPORT IT, works in conjunction with the text in your body copy.
The meta keyword tag is also sometimes useful as a way to help your page come up for synonyms or unusual words that don't appear on the page itself. For instance, let's say you had a page all about the "Penny Black" stamp. You never actually say the word "collecting" on this page. By having the word in your meta keywords tag, then you may help increase the odds of coming up if someone searched for "penny black stamp collecting." Of course you would greater increase the odds if you just used the word "collecting" in the body copy of the page itself.
Here's another example. Let's say you have a page about horseback riding, and you've written your page using "horseback" as a single word. You realize that some people may instead search for "horse back riding," with "horse back" in their searches being two separate words. If you listed these words separately in your meta keywords tag, THEN MAYBE FOR THE FEW CRAWLERS THAT SUPPORT IT, your page might rank better for "horse back" riding. Sadly, the best way to ensure this would be to write your pages using both "horseback riding" and "horse back riding" in the text -- or perhaps on some of your pages, use the single word version and on others, the two word version.
I'm using all these capital letters on purpose. Far too many people new to search engine optimization obsess with the meta keywords tag. FEW crawlers support it. For those that do, it MIGHT! MAYBE! PERHAPS! POSSIBLY! BUT WITH NO GUARANTEE! help improve the ranking of your page. It also may very well do nothing for your page at all. In fact, repeat a particular word too often in a meta keywords tag and you could actually harm your page's chances of ranking well. Because of this, I strongly suggest that those new to search engine optimization not even worry about the tag at all.
Even those who are experienced in search engine optimization may decide it is no longer worth using the tags. Search Engine Watch doesn't. Any meta keywords tags you find in the site were written in the past, when the keywords tag was more important. There's no harm in leaving up existing tags you may have written, but going forward, writing new tags probably isn't worth the trouble. The articles below explores this in more detail:
The Search Engine Report, Oct. 1, 2002
The Search Engine Report, Dec. 5, 2002
Still want to use the meta keywords tag? OK. Look back at the opening example. See the second meta tag shown, the one that says "name=keywords"? That's the meta keywords tag. The keywords you want associated with your page go between the quotation marks after the "content=" portion of the tag.
Inktomi says that you should include up to 25 words or phrases, with each word or phrase separated by commas. More advice from Inktomi can be found on its Content Policy FAQ.
FYI, in the past, when the tag was supported by other search engines, they generally indexed up to 1,000 characters of text and commas were not required.
One other meta tag worth mentioning is the robots tag. This lets you specify that a particular page should NOT be indexed by a search engine. To keep spiders out, simply add this text between your head tags on each page you don't want indexed. The format is shown below (click on the picture if you want to copy and past the HTML for your own use):

You do NOT need to use variations of the meta robots tag to help your pages get indexed. They are unnecessary. By default, a crawler will try to index all your web pages and will try to follow links from one page to another.
Most major search engines support the meta robots tag. However, the robots.txt convention of blocking indexing is more efficient, as you don't need to add tags to each and every page. See the Search Engines Features page for more about the robots.txt file. If you use do a robots.txt file to block indexing, there is no need to also use meta robots tags.
The meta robots tag also has some extensions offered by particular search engines to prevent indexing of multimedia content. The article below talks about this in more depth and provides some links to help files. Search Engine Watch members should follow the link from the article to the members-only edition for extended help on the subject.
Image Search Faces Renewed Legal Challenge
The Search Engine Report, August 22, 2001
There are many other meta tags that exist beyond those explored in this article. For example, if you were to view the source code of this web page, you would find "author," "channel" and "date" meta tags. These mean nothing to web-wide crawlers such as Google. They are specifically for an internal search engine used by Search Engine Watch to index its own content.
There are also "Dublin Core" meta tags. The intent is that these can be used for both "internal" search engines and web-wide ones. However, no major web-wide search engine supports these tags. More about them can be found below:
How about the meta revisit tag? This tag is not recognized by the major search engines as a method of telling them how often to automatically return. They have never supported it.
Overall, just remember this. Of all the meta tags you may see out there:
At the bottom of this page are more resources about meta tags, including tutorials and meta tag building applications. But first.
If you've been following the "Next" buttons to read the numbered sections of the Search Engine Submission Tips guide in order, you've now reached the last page. Congratulations!
There's still more information you might find helpful, however. Please review the pages listed under the Optional But Helpful section for additional assistance with search engine marketing issues.
In addition, do consider becoming a Search Engine Watch member, for access to even more information on search engine marketing issues.
Just started learning from this page? Don't worry -- click here to go to the beginning of the guide.
Now, here are those additional meta tag resources and articles.
Site Announce Meta Tag Generator
Simple, free online form that creates basic meta tags for your web pages.
This is a software-based package for Windows that creates meta tags. It is a freeware package -- no registration fee required.
This form allows you to create very complicated meta tags using much more than the keywords and description tags, if you wish. Note that it will place a commented credit line into the tag. This can easily be removed, if you wish.